




Achieving high reliability in artificial intelligence (AI) systems, such as autonomous vehicles navigating through snowstorms or medical AI diagnosing cancer from low-resolution images, hinges on model robustness. While data augmentation has long been a favored technique to enhance this robustness, the specific conditions under which it works best have remained elusive—until now.
Professor Sung Whan Yoon and his research team from the Graduate School of Artificial Intelligence at UNIST have unveiled a new mathematical framework that clarifies when and how data augmentation can bolster a model’s resilience against unexpected changes in data distribution. This breakthrough not only paves the way for more systematic and effective design of augmentation strategies but also promises to accelerate AI development significantly.
Understanding Model Robustness
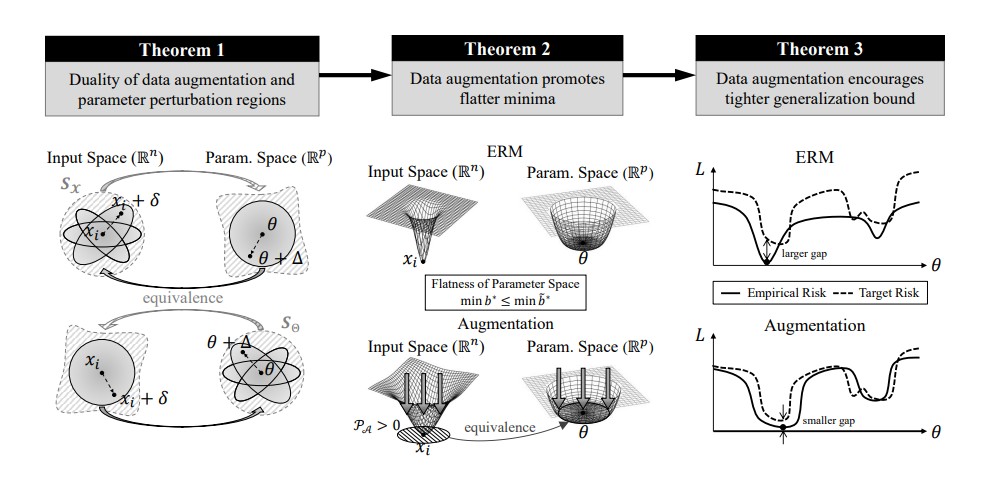
Model robustness refers to a model’s ability to generalize well across unforeseen distributional shifts, including data corruptions and adversarial attacks. Data augmentation, a process that involves creating modified versions of training data, has been a cornerstone in enhancing this robustness. However, selecting the most effective transformations has traditionally been a process of trial and error.
The research team identified a specific condition, termed Proximal-Support Augmentation (PSA), which ensures that augmented data densely covers the space around original samples. This condition, when met, leads to flatter, more stable minima in the model’s loss landscape. Flat minima are associated with greater robustness, making models less sensitive to distribution shifts or attacks.
Experimental Validation and Implications
Experimental results have confirmed that augmentation strategies satisfying the PSA condition outperform others in improving robustness across various benchmarks. This development follows rigorous simulations on common corruption and adversarial robustness benchmarks, utilizing datasets such as CIFAR and ImageNet.
Professor Yoon explained,
“This research provides a solid scientific foundation for designing data augmentation methods. It will help build more reliable AI systems in environments where data can change unexpectedly, such as self-driving cars, medical imaging, and manufacturing inspection.”
Academic and Industry Impact
This work has been accepted as an official paper at the 40th Annual AAAI Conference on Artificial Intelligence (AAAI-26), held at the Singapore Expo from January 20 to 27, 2026. The study was supported by the Ministry of Science and ICT (MSIT), the Institute of Information & Communications Technology Planning & Evaluation (IITP), the Graduate School of Artificial Intelligence at UNIST, the AI Star Fellowship Program at UNIST, and the National Research Foundation of Korea (NRF).
The announcement comes as AI systems are increasingly integrated into critical areas such as healthcare, transportation, and manufacturing. The ability to ensure these systems remain reliable under varying conditions is paramount.
Future Directions and Challenges
While the framework provides a robust theoretical basis for data augmentation, practical implementation in diverse AI applications remains a challenge. As AI continues to evolve, the need for adaptable and resilient models becomes more pressing. The move represents a significant step towards achieving this goal, but further research and collaboration will be essential to fully realize its potential.
According to sources, ongoing studies aim to refine these augmentation strategies further, potentially leading to new standards in AI model training. The implications of this research extend beyond immediate applications, offering insights that could influence future AI innovations.
As the field of artificial intelligence advances, the insights provided by Professor Yoon and his team are expected to play a crucial role in shaping the future of AI robustness and reliability.


